





Natural Language Processing (NLP) technology is nothing new. It has already seeped into our daily lives. This technology is what completes your keyword search before you finish typing, similar to how your AI assistant processes your voice command. A chatbot is an NLP application that is driving a huge part of the automation revolution.
Even though it isn’t as good as human customer service (no way near actually, from my experience), 24/7 immediate response capability and reduction in cost are what is attracting many companies to adopt this technology. If you’ve thought that these are the end of the road for NLP and polishing up the technology for existing applications is all that is left, think twice.
Recently released GPT-3 is showing a glimpse of what the next level NLP looks like. It appears that the next level of NLP implies so much potential to change the business landscape. Even if you are not an A.I. enthusiast, you might have heard people talking about GPT-3. GPT-3 is a computer program created by a non-profit artificial intelligence research laboratory OpenAI in San Francisco. If you haven’t heard about GPT-3 check out some unbelievable results from the advanced NLP models below.
GPT-3, unlike its predecessor GPT-2, is not open to the public and only available for selected developers as a closed beta service. However, the cases mentioned above are just a few examples that I’ve found based on research on the internet. Even with the given limitation of accessibility to the model, the used cases show that GPT-3 can be programmed to write an article, that can be easily passed off as written by a human; make webpage designs; write a computer code from plain English description; and simulate dialogue with a historic figure. This is insane!
Since it isn’t the easiest thing for a non-expert in machine learning to comprehend what GPT-3 is (wasn’t easy at least for me), let’s break down GPT-3 in a simple language understandable by everyone – What is happening under the hood of this text generating model? Why is it attracting so much attention? What are the anticipated obstacles? Let’s go through them one by one.
Why is GPT-3 so good?
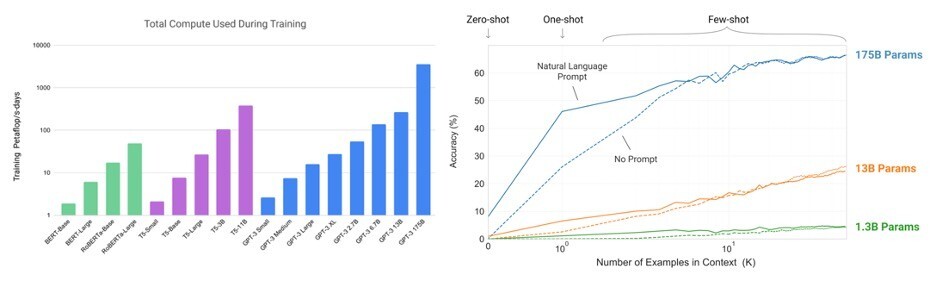
175 Billion parameters, and Few shot Learning [i]. These are the words you would often encounter when you search for information about GPT-3. What is a parameter and what does this number, 175 billion, mean?
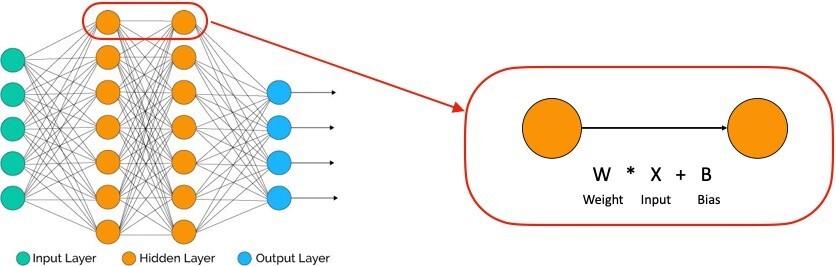
On the left, this is how the deep learning model looks like. Just like many other machine learning algorithms, deep learning is an algorithm that tries to find an optimum weight(W) that minimizes the bias(B). Thinking about simple linear regression would help the intuition.
However, as you can see from the diagram, deep learning consists of multiple connections that contain the weights. We call each of these weights a ‘parameter’ and GPT-3 consists of 175 billion parameters that define the relationship between nodes. As mentioned above, the deep learning model works in a way of finding optimal W that minimizes B and then the model repeats the training (we call each trails epoch) of the data set which updates to more optimal parameters.
A change in a single parameter will influence the whole model because of the interconnectivity and so you can imagine the complexity of a model that consists of 175 billion parameters, right? OpenAI trained the model using 45TB web-scraped text data (which filtered down to 570GB after tidying the data) plus some other data sets from other sources such as books and Wikipedia. The total data set consists of 499 billion tokens (token refers to the smallest unit that a corpus consists of).
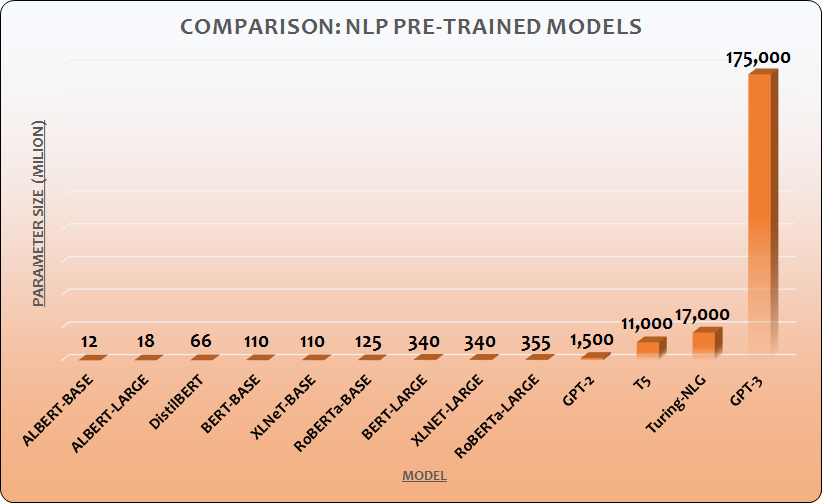
Why is this figure, 175 billion parameters, important? It is because the success of GPT-3 implies that the size of the model matters. The machine learning model architecture of GPT-3 is a transformer-based neural network. This architecture has been around since 2017 and it has been quite popular for a while. Google’s NLP model BERT and GPT-3’s previous version GPT-2 are both using transformer-based architecture.
The most important factor that makes GPT-3 such a high performing and human-sounding is the size of the model. This means that with a bigger size you can have a more sophisticated NLP model. What is ‘few shot learning’ then? Before we deep dive into few shot learning, let me introduce you to the concept of transfer learning and fine-tuning. To understand these concepts easier, let’s assume that I have trained a deep learning model that can identify an animal species from an image.
I have trained the model to identify hundreds of animal species, and you want to make an application that can tell the difference between cats and dogs. If my model can successfully identify cats and dogs from an image without any further data, it is zero shot learning model. If the model can perform after you give one image of a cat and one image of a dog respectively, it is one shot learning.
Few shot learning is when the model works after giving fewer than 10 examples. We call this process ‘transfer learning’ (zero shot learning doesn’t require any transfer learning). Usually, transfer learning for NLP model requires thousands of examples. What you would want to do is take advantage of a pre-trained model (that’s the whole point of transfer learning) and then update the model to reflect the newly added task-specific examples.
This process is called fine-tuning. In addition to the initial training of the model, fine-tuning itself is a very elaborate process. Few shot learning is an enormous breakthrough for NLP model! GPT-3 had a big enough size that the model that had mastered the structures of human-generated texts and after looking into a couple of examples it can perform similar tasks. Think about it. GPT-3 can be a journalist, a programmer, a scriptwriter, and so many other things after feeding it a few examples.
What are the shortcomings?
I am pretty sure that you are super excited about this technology at this point. But is GPT-3 really a Deux ex Machina for NLP? No. The answer is No. There are certainly a lot of hypes (quite some contribution from the media) around GPT-3 and I can say this with 100% confidence because this is what came out of OpenAI CEO Sam Altman’s mouth.
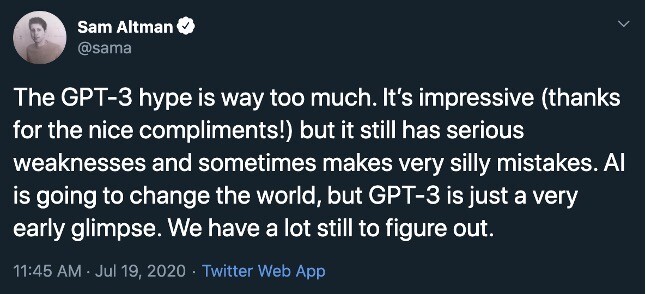
How would GPT-3 look like after adding the right dosage of reality? Let’s talk a little about the caveat – the limitation of GPT-3. Before we move on to this specific topic, let me provide clarity on one thought. GPT-3, although it seems like it understands the context of the text like humans and generates the output, is not comprehending things. The output GPT-3 comes out with is not an outcome of logical inference.
All it is doing is looking at the text you’ve fed into the model and presents an outcome based on a statistical likelihood. If you’re giving it a common sentence it will perform well, but when you give the model something unusual it will present an absurd output based on statistical likelihood (here’s my personal favorite, English speaking unicorn experiment).

The creators of GPT-3 also points out the limitation of GPT-3 in their paper. “Although as a whole the quality is high, GPT-3 samples still sometimes repeat themselves semantically at the document level, start to lose coherence over sufficiently long passages.”
Also, GPT-3 which has been trained using text from the internet, also has some gender and racial bias issues. Below are some examples when GPT-3 was prompted to write tweets from one word – Jews, black, women, holocaust. We don’t know what’s OpenAI’s plan for addressing this problem but companies would certainly not want to use a racist A.I. system.

Another problem is that the model will decay over time. What do I mean by this? As mentioned above GPT-3 was trained using a dataset from 2016 to 2019. It means GPT-3 knows nothing about what happened after 2019. For instance, the model doesn’t know about Covid-19. Now when we talk about ‘social distancing’ or ‘lock down’ we would all understand it with the context of a pandemic situation, but GPT-3 is not capable of doing so because it never learned about it.
What is relevant now might not be as relevant in the future and pretty much all machine learning models in a sense are open to the threat of model decay. However, human society is very versatile, and therefore NLP, which is an algorithm processing human language is more prone to model decay. Of course, this problem is often addressed by re-training the model using a new dataset. But considering the size of the model, it is very consuming and requires a budget.
Finally, GPT-3 is a few shot learner capable of performing quite a range of general tasks. While this may be true, if you want to make GPT-3 to perform a specialized task it might not be the best model. OpenAI is also very aware of it and the CTO Greg Brockman hinted that they will add the fine-tuning feature in the future. In fact, I’m pretty sure OpenAI is aware of all the problems I’ve stated above and more. Whether OpenAI is going to successfully address these problems and become a game-changer is something I cannot answer right now, but it will be revealed soon as OpenAI expand their API customer base.
Where is GPT-3 now?
OpenAI’s GPT-3 is not likely to be open-sourced. Microsoft has exclusively licensed GPT-3 technology and OpenAI is only planning to provide GPT-3 through subscription-based API access. The cost for training GPT-3 for OpenAI was approximately $4.6 million. I think the size and complexity of the model justify the cost.
But then what about the price? OpenAI announced GPT-3 API’s price scheme in September 2020, which started to take effect to begin the 1st of October 2020. GPT-3 is still on beta service and this price pricing scheme for beta service seems adjustable, yet there are lots of mixed reactions from the A.I. community.

A large part of the negative reaction attributes to the fact that OpenAI is a non-profit organization. OpenAI describes their mission as “to ensure that artificial general intelligence (AGI)—by which we mean highly autonomous systems that outperform humans at most economically valuable work—benefits all of humanity.” Given the track record that GPT-2 was open-sourced, there have been some reactions from the crowd who thinks OpenAI has lost their original intention.
OpenAI explains themselves by releasing commercial products on their official website “Ultimately, what we care about most is ensuring artificial general intelligence benefits, everyone. We see developing commercial products as one of the ways to make sure we have enough funding to succeed.” However, increasing the price from free to $100 per month is still a huge difference and the introduction of a pricing scheme is expected to drive out the hobbyist from their beta customer list and target the start-ups/corporate users.
A few shot learner NLP API is not really something that has been around in the market and hence whether this pricing is too high or not is still very controversial. OpenAI explains two million tokens will be sufficient to process 3,000 pages of text. They also added that it will take 1.2 million tokens to process the entire works from Shakespeare. On the other hand, Murat Ayfer, a developer of Philosopher AI which generates interesting text-based on a single keyword or phrase using GPT-3, has a different view.
From an interview with Computer Business Review, he stated “So far PhilosopherAI.com has had 850,000 queries entered and generated 612,949,783 characters. This would cost around $6,000 if it was all generated in one go, but the background prompt juggling I do probably multiplies it by three, putting me at close to $18,000 already.”
What do you think about the pricing scheme from OpenAI? Is it too pricy? Should the token be the base of the pricing scheme? We don’t know the applications and business models for those applications yet. How should we approach pricing in this case? This could be a perfect material for a business school case study. If anyone reading the article has thoughts to share, I’d be happy to discuss it.

To cover the cost of initial training and operation costs that will incur, OpenAI will need quite a number of subscribers for their API. There are some startups who’ve already launched their service powered by GPT-3 at this early stage. Here’s a fun example. Latitude has introduced a GPT-3 powered text-based adventure game. Their product is called AI Dungeon, and it was initially launched in December 2019.
Its original version is powered by GPT-2 and it’s freely available for you to try it. They’ve also recently launched a premium version of AI Dungeon called AI Dungeon Dragon powered by GPT-3 ($9.9 per monthly subscription). There aren’t many yet, but I believe there is going to be a lot of products released in the near future. You could take your MBA lenses on and think about some clever applications!
This article was originally published on LinkedIn.
[i] Tom B. Brown. (2020). Language Models are Few-Shot Learners. arXiv:2005.14165.
[ii] Soheil Tehranipour (2020). https://medium.com/analytics-vidhya/openai-gpt-3-language-models-are-few-shot-learners-82531b3d3122
[iii] Kevin Lacker (2020). https://lacker.io/ai/2020/07/06/giving-gpt-3-a-turing-test.html